tesseract-ocr
Latest reviews
tesseract --list-langs returns only english, with absolutely no direction on where to find and how to install other languages. Generally this is only for programmers. If you are an ordinary person and you think you are going to give a simple command with a source file and a selected language and get results, this ain't gonna happen.
For the german lawyer postal service (beA) I needed that function, but it didn't seem to work with PDF as a basis. Then I installed OCRmyPDF and with both programs together, you're good to go! Any PDF will be seachable! Great!
Very helpful if you need to ocr a document quickly without installing a lot of software! A few minor corrections to the text need to be made.
Es un buen programa. Si lo instalas, recuerda que tienes que añadir también el archivo de idioma correspondiente (tesseract-ocr-spa --> para español; o los que necesites). Ten en cuenta que se trabaja desde la consola con archivos .tif [p. ej.: tesseract archivo.tif archivo-resultante -l spa]. Si quieres algo más visual, tienes, además, que instalar un programa que se llama YAGF (lo hallarás en los repositorios). De esta manera podrás trabajar en un entorno gráfico con selección de áreas para realizar el OCR, etc. Para terminar de completarlo, puedes añadir otro programa llamado CUNEIFORM.
The tesseract engine provides recognition of German Fraktur script - and to my (limited) knowledge, no other free ocr engine provides that. I think that's awesome!
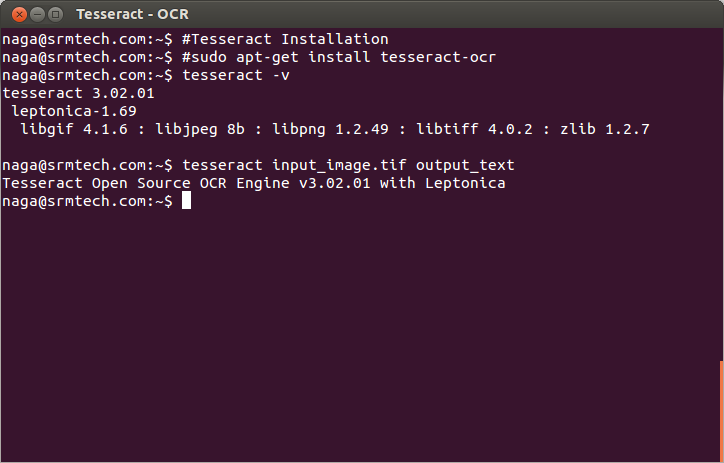
One of the most accurate free software OCR engines that handles image files in TIFF format (with filename extension .tif); other file formats need to be converted to TIFF before being submitted to Tesseract.