What about a well-furnished dictionary ?
|
10 years ago 2 |

Introduction
While spelling dictionaries of the likes of a-, i-, my- and hunspell were and are still common in the UNIX and Linux world, and in open source software in general, the usage of explanatory and bilingual dictionaries and also thesauri mostly requires proprietary software. This is probably because their editing is rooted in a tradition which is centuries old, whereas automatic spelling became only possible — and necessary — when text begun to be edited with computers.
Nevertheless, these kinds of reference dictionaries are indispensable if you need to translate some text, be it shorter or longer, in any given language outside a web browser, or when you’re offline. All in all, we have the following alternatives:- online dictionaries which maybe reflect the modern usage of a spoken language, but which are neither complete nor accurate;
- free offline dictionaries which may be complete, but which are most likely to be free of copyright issues only when they’re really dated;
- non-free offline dictionaries which are both up to date and complete, but which ask for a paid license.
Hence, the best would be to find an optimal mix of all these resources, and a look-up program that could easily cope with all of them. The package named GoldenDict is such a dictionary viewer.
 The viewer
The viewer
Actually, the viewer we’re going to use is a kind of a slim web browser which is based on the same WebKit rendering engine as Cinnamon. Its concept comes in handy when local dictionaries and web pages are to be displayed together as a result of a query. Once properly configured, we don’t need to bother where the sources are located, and even the choice of correct dictionaries will follow the session’s current language.
The GoldenDict package can be installed easily from the Software Manager. When we’ll be done with this tutorial, you’ll be able to look up any word or text fragment in all your relevant dictionaries at once like in the following picture, and this function will be at your fingertips with a single keypress from within any application if you take care to select that text beforehand:
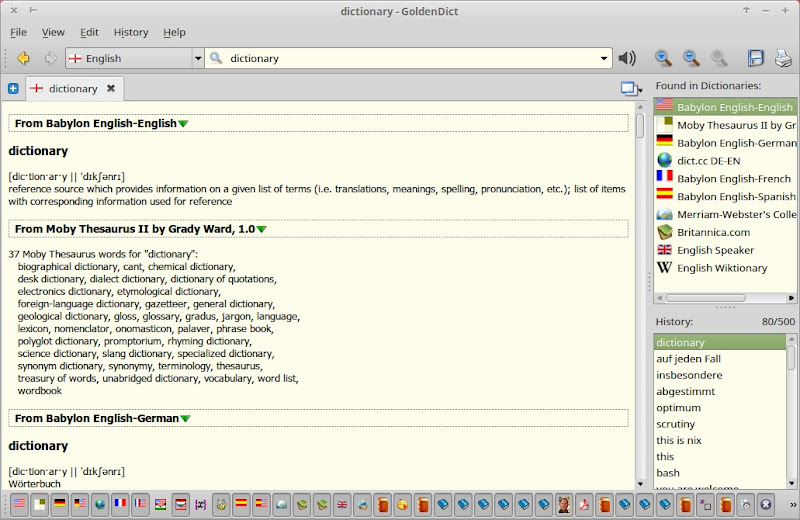
The very first step
At the very beginning, you should uncheck the Edit› Preferences› Scan Popup› Enable scan popup functionality, otherwise you’ll get tired of GoldenDict even before you start using it. That is to say, with the first dictionary just installed, you’ll be bugged by an unprompted popup as soon as you select some text. Thus better disable this — after all, we want the dictionary to help us and not to get into our way 
 1. External tools
1. External tools
You’ll need three additional utilities which can all be installed from the Software Manager as usual:
- xsel to manipulate the selected text;
- espeak, a speech synthesizer to give an idea about the pronunciation of unknown words;
- uzbl, a lightweight web browser to visualize contents like Google Translate which cannot be rendered inside a GoldenDict window.
… $ echo export XDG_DOWNLOAD_DIR=\"\$HOME/Downloads\" >> ~/.profile
This web browser is a very basic (but fast) one, which has the advantage of displaying web pages as GoldenDict would because it’s based on WebKit too, even if it has no buttons to navigate. It has just a few control keys which you can take a look at in your favorite browser with the following command:
…$ x-www-browser http://uzbl.org/keybindings.phpSave that page from the browser to your download folder, and move it over to the configuration directory of uzbl (note the ’_’ replacing the space in the name):
…$ mv ~/Downloads/Uzbl\ Keybindings.html ~/.config/uzbl/Uzbl_Keybindings.htm
This help file will be available in the Uzable Browser if it’s assigned to the [H] key (bear in mind that such keys are case sensitive in uzbl). This can be done by executing a last command, viz. the following one:
…$ echo @cbind H = event REQ_NEW_WINDOW file://@config_home/uzbl/Uzbl_Keybindings.htm \ >> ~/.config/uzbl/config
 2. Dictionary files
2. Dictionary files
Of the many dictionary packages available from the Software Manager, there are only a few which are really usable. So here’s the editor’s choice:
- The Moby thesaurus is a large and comprehensive English thesaurus which concentrates on synonyms rather than on some fancy relationships between them as it is the case with thesauri derived from the WordNet project;
- The bilingual dictionaries of the FreeDict project which can be found in the Software Manager by searching for “freedict”. They are quite good (and free
 ), but the lack of a title once a package has been installed is somewhat embarrassing with regard to its handling in GoldenDict.
), but the lack of a title once a package has been installed is somewhat embarrassing with regard to its handling in GoldenDict.
/usr/share/dictThen, create a new folder named .dict in your home folder. Naming it this way will make it invisible, unless you let Nemo View› Show Hidden Files (or toggle its display with [Ctrl+H]). Anyway, this will be the place where non-packaged dictionaries have to be downloaded, so state it as another recursive path in GoldenDict as:
~/.dict
Local dictionaries have to be indexed, which occurs automatically by quitting and restarting the program.
 3. Other dictionaries
3. Other dictionaries
If you need more than you can get from the Debian-Ubuntu-Linux Mint repositories, then you have two options basically, both of them being “free”, but in the two different meanings of the word:
- First, there is a collection of dictionaries at http://www.personal.leeds.ac.uk/~ecl6tam/Downloadable/GoldenDict%20Dictionaries.html, compiled especially for GoldenDict by Alec McAllister from the University of Leeds. As the dictionaries therein all have GPL and analogous licenses, they’re free as in free speech

- Second, if you’re still not satisfied, you’ll have to swallow your pride, and take a look at the almost unique alternative that can be used. This one might be more professional, but it’s only as free as a free beer — at least at first sight. Because this beer is moldy: any dictionary on their website requires a valid license to use it

In any event, the dictionaries have to be placed into the ~/.dict folder from above. It’s more clear to make up a subfolder there for each language, e.g. English, French, etc. If they come bundled within an archive of some sort, you have to unpack the dictionaries of your choice, for instance by dragging them from the Archive Manager to that folder. As mentioned in the precedent section, don’t forget to restart GoldenDict afterward.
 4. Pronunciation
4. Pronunciation
In online dictionaries, it’s a common feature nowadays to get the words pronounced. But to have that feature accessible offline, by means of audio files organized like a dictionary e.g., is even more challenging than to find a good dictionary. There are none in the repositories, and they are hard to find on the net.
Thus the only collection for English that I can recommend is the one that can be found on the website of the LightLang dictionary project which is of good quality and contains 21056 entries. Once downloaded, unpack the en folder of the archive into a (new) subdirectory of your dictionary folder which you should Add… to your dictionaries under the [Sound Dirs] tab. These sound resource has to be given a name too:Path: ~/.dict/sound/en Name: en Sound Icon: /usr/share/cinnamon/applets/keyboard@cinnamon.org/flags/gb.png
The local pronunciation files installed there can be listened to either by making GoldenDict: [F4] (Edit› Preferences›) Audio› Playback› Use (an) external program like mplayer, or by letting it Use (the) internal player, which is faster but needs espeak to be configured as an external (!) program.
Besides, there are also high quality packages for French which can be downloaded form the website of the Shtooka project. Unfortunately, they have a special format that needs a dedicated software to decode, which doesn’t compile easily on Linux Mint 17.x. Hence, it’s easier to use the site as it is, and to set it up as an online resource as shown in the next section.
 5. Online resources
5. Online resources
If we were to constitute a dictionary for English not as a foreign language, but as a native one, we could as well take French as the language to look up, so the Shtooka website could serve us as an example . That is, we should Add… it as a [Website] to our dictionaries with the following parameters:
Enabled: ✕
Name:::: Projet Shtooka
Address: http://shtooka.net/listen/fra/%GDWORD%
The trick is to replace the word to look up, e.g. “dictionary” as in the screenshot above, by the template %GDWORD% in the address of the online dictionary’s query page. This works for any website that displays the targeted word in the address bar of a browser, so for example the dict.cc online dictionary which I consider one of the best resources for the language pair German–English. Hence, you could query this dictionary with the following URL:
http://www.dict.cc/?s=dictionary
→ http://www.dict.cc/?s=%GDWORD%
Like any other resources, websites can be assigned icons in the [F3] Dictionaries› Sources› (or later the Groups›) dialog, provided you scroll it far enough to the right. For instance, you could choose an image from the folder /usr/share/cinnamon/applets/keyboard@cinnamon.org/flags. If you manage to download the site’s logo, you can use it too. A convenient place to store your icons would be another subdirectory of the dictionary folder (the icon’s location should be first copied from its context menu in Nemo, and then pasted into the dialog):
~/.dict/images
However, if a query web page doesn’t render in a GoldenDict window, e.g. because openjdk-7-jdk or any other Java package doesn’t allow for it (saying “Vector smash protection is enabled” instead), you’ll have to access it via an external program.
 6. External commands
6. External commands
One of the most prominent websites that doesn’t work for me in GoldenDict is Google Translate. At the same time, it’s the most easiest thing in the world to make it work in a window of its own. All it takes is to Add… it as a [Program] with the following description:
Enabled:::::: ✕ Type::::::::: Html Name::::::::: Google 2 en Command Line: uzbl https://translate.google.com/?hl=en#auto/en/%GDWORD%The “program” above is basically the same web address which would stand under [Websites], i.e. an address with the query word replaced by “%GDWORD%”, augmented with the name of the browser which is to display it. The command given will translate any fragment of text — by detecting its language automatically — to English which is specified as usual by en. If you need to translate to another target language, you have to substitute this with the code of that language in the description fields. Supposing your current session is running in this language, you can determine its code just by pasting the following command line into a terminal:
…$ echo $LANG | head -c2 >> echoThe same principle applies to the word-reading application. As all these resources will be handled by GoldenDict in exact the same manner as any dictionary, a reader should be defined for each language you’re using. That is, the language code must match the target language, so for example in the case of English:
Enabled:::::: ✕ Type::::::::: Audio Name::::::::: en Speaker Command Line: espeak -v en %GDWORD% Icon::::::::: /usr/share/doc/espeak/docs/images/lips.pngNow, let’s suppose that you have downloaded some free grammar book to the dictionary folder as a PDF. You can then look up any grammatical term like in a dictionary simply by calling the Document Viewer, but you have to insert your username into the path leading to the file:
Enabled:::::: ✕
Type::::::::: Html
Name::::::::: English Grammar
Command Line:
evince --find=%GDWORD% file:///home/your_username_here/.dict/free-english-grammar.pdf
Icon::::::::: /usr/share/icons/Mint-X/apps/scalable/evince.svg
 7. MediaWiki-based sites
7. MediaWiki-based sites
GoldenDict comes with some Wikipedia and Wiktionary sites preconfigured, but I prefer to use the English Wiktionary exclusively for two reasons:
- I’ve got Configurable Menu to look up things directly in the Wikipedia corresponding to my session already, and that works so well that I don’t need to duplicate its function;
- From a linguistic standpoint, the English version of Wiktionary is the most complete and accurate, even with regard to entries in other languages, so it’s the most useful to me.
But if you don’t get along with this setting, you can configure any Wikipedia or Wiktionary site of your liking by adapting the default examples to your needs, of course.
 8. Spelling dictionaries
8. Spelling dictionaries
You don’t have to care much about these dictionaries, as they’re available by default in Linux Mint. That is to say, the spelling dictionaries of Hunspell get installed automatically when you add a new language in System Settings› Language (Settings)› Language› Language support, because it’s those packages that do the work in the background when LibreOffice or a web browser needs spell checking.
GoldenDict uses them to provide stem words and make spelling suggestions for your searches. Just mark the ones you need, and leave the directory path at its default setting which is:/usr/share/myspell/dicts
 The right look-up order
The right look-up order
Now that you’ve installed all your offline dictionaries and configured the other sources, you should organize them. Since anything you’ve added is regarded as a dictionary, you could set up the order that you wish the searches to follow under the tab [Dictionaries] simply by dragging them around. But as you’ll inevitably end up adding new dictionaries at the end of that list, arranging them there is superfluous.
Why ? Because your dictionaries should be grouped according to their language — which would be the language of your user interface ideally — and ordered following their importance (and speed). GoldenDict offers to sort all your dictionaries in language pairs, but I think this isn’t an idea as good as it sounds, since translations are often needed from and to the same language. Another important fact that impacts on grouping is the ability of a source to render within GoldenDict. As a starting point, you can take on the following advices drawn from my own experience with the matter.
With reference to our examples so far, you should Add (a) group named “English” in the [F3] Dictionaries› Groups› dialog by choosing “England” as a Group icon. You should add the following items from the Dictionaries available by dragging them into the Groups window — or by copying them by clicking on [>] — in the following order:- a monolingual reference like the first dictionary in the screenshot above or the Merriam-Webster’s;
- a dictionary of synonyms like the Moby Thesaurus;
- your preferred bilingual dictionaries in the sequence of the frequency of their use (by taking care to place slower online resources down the list);
- specialized dictionaries like the Hacker’s Jargon or American English;
- the en Speaker, preceded by the en Sound, if available (these resources won’t be used directly unless the loudspeaker icon beneath the search field in GoldenDict doesn’t work for some reason);
- the English Wiktionary;
- and last but not least, the corresponding morphology dictionary.
- “English” as set up like before;
- “Google Translate” with Google 2 en as its sole dictionary;
- “Grammar” with the English Grammar book.
Proceed like this for each language which you’ve configured dictionaries for, possibly assigning some of them to several groups, e.g. in the case of any bilingual variant. This way, the purpose of your groups will be clear, and they can be made to adapt to the desktop’s language.
Automatic language selection
This step isn’t imperative, it just makes it more convenient to return to the default dictionary group after having messed around with the others: you stop GoldenDict with [Ctrl+Q] from its main window or with the mouse in the panel, and the next time you need it again, it’ll start up with a dictionary group that matches the current language of your desktop.
It isn’t that difficult to install this feature though. It works via a small intermediary script that must be first made up with the following sequence of terminal commands (as usual you can copy’n paste them) — remember, the sudo command requires your password:…$ sudo touch ~/usr/local/bin/goldendict …$ sudo chmod +x ~/usr/local/bin/goldendict …$ gedit ~/usr/local/bin/goldendict
The last command opens up the Text Editor where you’ll have to paste in the following content and to save the file — that’s it:
#!/bin/bash
# /usr/local/bin/goldendict (MagicMint) O0820
# A proxy for GoldenDict to set the correct dictionary group
# (ɔ) GPL-2, see /usr/share/common-licenses/GPL-2
CONF=~/.goldendict/config
# Take the first group which has a flag corresponding to the current language
GROUP=$(awk -F 'id="' "/group icon=\"`echo $LANG | head -c2`/{print \$2}" \
$CONF | head -1 | cut -d'"' -f1)
echo Group id = $GROUP
# Make that group the default one
sed -i "/<lastMainGroupId>/s/<lastMainGroupId>.*</<lastMainGroupId>$GROUP</" $CONF
sed -i "/<lastPopupGroupId>/s/<lastPopupGroupId>.*</<lastPopupGroupId>$GROUP</" $CONF
# Start the viewer
exec /usr/bin/goldendict "$@"
#End of script
The best of it all
As @xenopeek suggested it on the forums, single words can be looked up with a unique keypress from within any application, even from a terminal window or non-compliant editors like gvim. This idea  is just extended here to an arbitrary selection of text which is much more useful in terms of translation. Note that for the following to work in GoldenDict, you must not alter the built-in hotkeys of the program !
is just extended here to an arbitrary selection of text which is much more useful in terms of translation. Note that for the following to work in GoldenDict, you must not alter the built-in hotkeys of the program !
Name:::: Dictionary Command: bash -c "goldendict \"$(xsel|tr '\n' ' '|sed -r 's/^[^[:alpha:]]*([-[:alpha:]]*).*$/&/')\""You should bind this command to the [Super (Windows) + D] key (unless you need that negligible “Show desktop” function on this key absolutely
 ). This makes it possible to look up things in your dictionaries very simply and quickly by following these steps:
). This makes it possible to look up things in your dictionaries very simply and quickly by following these steps:
- Mark the text you want to translate by the mouse or the arrow keys;
- Press [Super+D] to call GoldenDict. It will show its main window if it starts at the moment, or it will pop up a floating window if it was running already. From the latter, you can send the query by means of a click on the book icon or with [Ctrl+W] to the main window which has more possibilities, if you want to. However, if the program is running in the background, its window can be opened without any query at all by pressing [Ctrl+F11+F11] at any time;
- In both windows, you can navigate either by clicking on a link (or the back and forward buttons), or by double-clicking on a word;
- You can mark a synonym or a translation there and copy it with the mouse or [Ctrl+C] to the clipboard as usual. If the selection concerns a locution, you perform it by dragging the mouse pointer along it, otherwise it suffices to click on a single word to select it — provided you’ve got [F4] Preferences› Interface› Select word by single click ticked;
- Once you’ve returned to your original application, you can paste the contents of the clipboard over the previously selected text in order to replace it — and you’re done in a jiffy…
On a final note, believe me or not, if you use dictionaries a lot, a thorough configuration of GoldenDict like this will really speed up your daily work — and you just have to do it once 
Comments
@MagicMint
No, gespeaker cannot be called from within artha. I generally copy the word to gespeaker to hear the pronunciation.
Artha also doesn't have multilingual translation capability.
I only need eng-eng, so it's kinda enough for me.
@jahid_0903014: Artha isn’t that bad, but as I’ve said above, I perceive the convoluted relationships in such Wordnet-based dictionaries as hindering. As for gespeaker, can you call it from within artha ?
Although the tutorial above is based on English as the base language — which you get the most complete dictionaries for — its real value becomes apparent when you need a few language pairs more in translations. Sometimes, it’s a real challenge…
I use artha though. It doesn't have much features but it comes with enough simplicity: one click install, keyboard shortcut to launch it with selected text, synonyms, antonyms, derivatives etc...
It doesn't have embedded wiki, pronunciation etc..
For pronunciation, I use gespeaker...
Thanks, guys. I would demote it myself too if there was a single-click install procedure for this ;-)
I considered dictionary usage a weak point of Linux until I came up with this slightly complicated but smoothly functioning solution. Now, it’s rather a USP for me…
@Rebel450
I was surprised too...as it was -3 when I promoted it...
So,
I read all these twice meanwhile and I cant get why someone should "demote"
this very good tutorial.
But when you ask 3 people for an opinion, you will have at least 4 different
opinions, so I dont care for that stpd promote/demote - crap anyway anymore.
Thanks to MagicMint,
sitting down and writing this tutorial for to help other people;
highly appreciated - and
"promoted" ;-) :-/